RWKV |
您所在的位置:网站首页 › docker 安装镜像 › RWKV |
RWKV
|
一、docker安装: 请自行百度,比较简单 windowswindows去官网下载个Docker Desktop Installer.exe文件 就可以直接安装了 注意点: 不管是安装软件还是后续安装镜像,对硬件稍微有点要求,默认安装的c盘(包含镜像),要有足够的空间,可以更改保存路径,请自行百度 linux:略过 请注意,需要本机电脑上cuda ≥11.1.1,更低的版本,暂未去搭建环境,会docker的可以自行去搭建二、镜像下载&运行:RWKV-v4neo 的训练拆分为两步: 1、数据集可以直接使用txt,也可以使用jsonl格式转成binidx格式的文件 好处:①大文件可以稍微省一些内存;②读取文件进行训练时速度比较快; 坏处:①gpt-neox的转化环境比较难搭建;②越大的文件转化时间就越长; 现在先解决gpt-neox的转化环境: 1、下载我已经搭建好环境的docker镜像(linux&windows都可以使用)ps:预计16-18个g docker pull linlinseo/my_gpt_neox:cuda11.1.1-cudnn8-devel-ubuntu20.04注意点: ①需要的10多个g的空间,如果默认到c盘的空间不够的话,自行百度,怎么转移至别的盘 ②需要电脑的驱动与cuda ≥11.1,可以看一下镜像的命令,具体的配置在上面都有 2、创建容器: 查看镜像: docker imageslinux sudo docker run --gpus all -it /bin/bashwindows docker run --gpus all --name 容器名 -d -t 镜像id ps:windows在使用 --gpus all 命令的时候会报图中错误,作者在win10上测试会报这个错,乌班图22.04则不会; 创建成功后自动以管理员进入环境 3、格式转换 linux: 进入目录 cd /home/gpt-neox/执行命令(带有一个测试的jsonl文件) python3 tools/preprocess_data.py --input ./my_data.jsonl --output-prefix ./data/my_data --vocab ./20B_tokenizer.json --dataset-impl mmap --tokenizer-type HFTokenizer --append-eod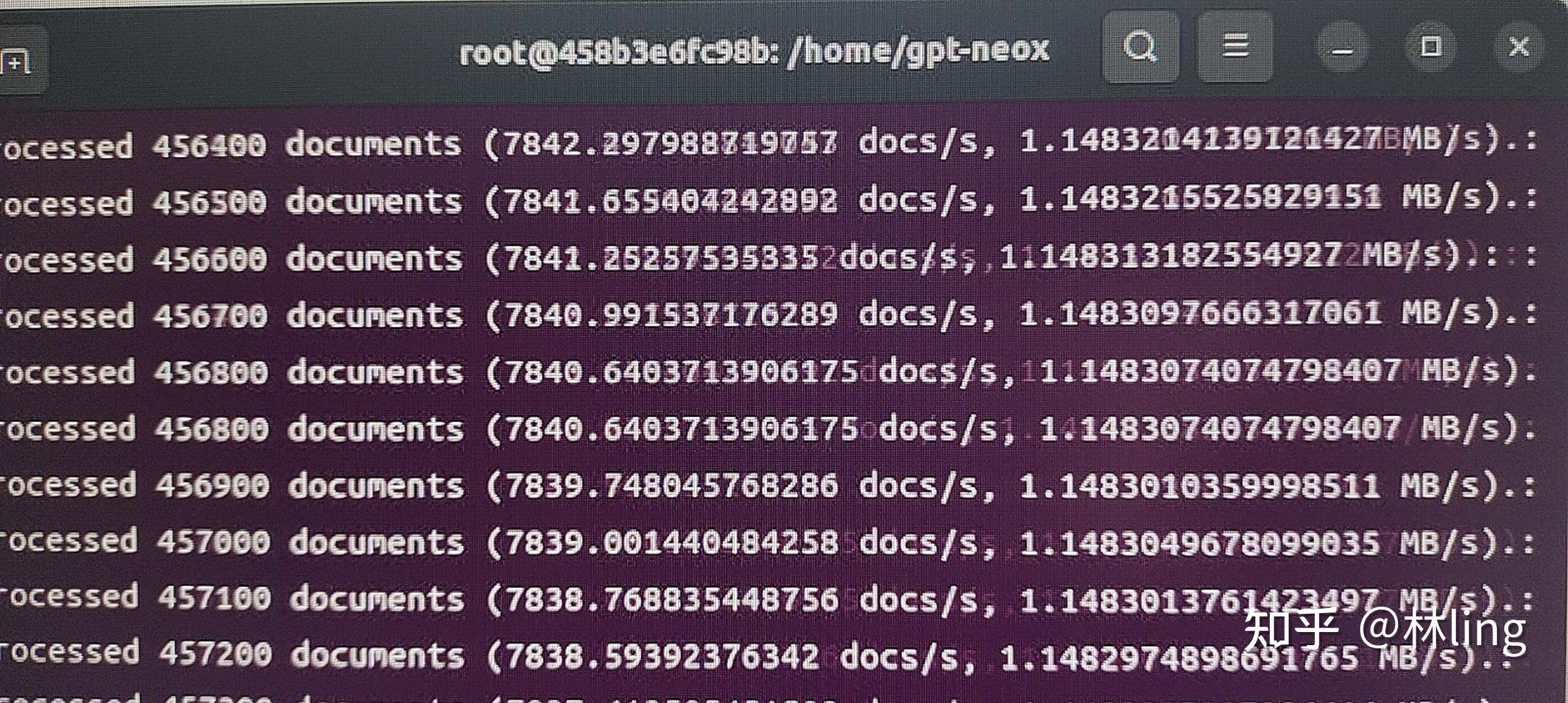 出现这种代表正在转换中; windows: 因windows的docker是直接有桌面版本 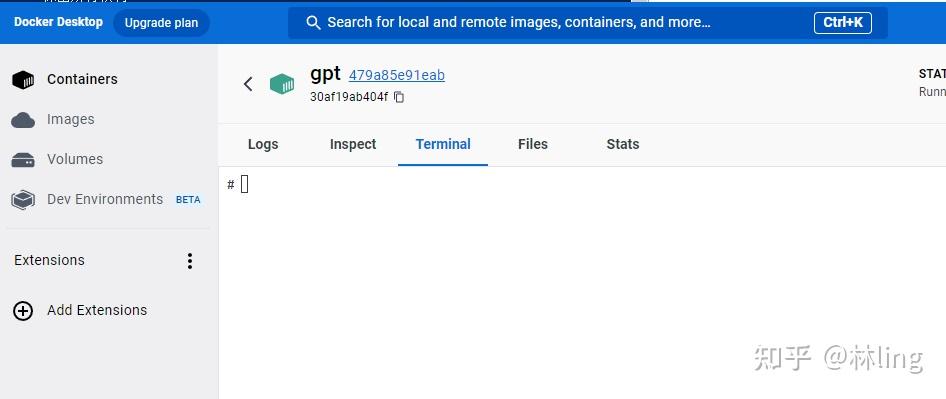 点击左侧的containers 在点击刚创建的容器 旁边的三个点,在点击 open in terminal,最后会出现如上图所示的页面 进入目录 cd /home/gpt-neox/执行命令(带有一个测试的jsonl文件) python3 tools/preprocess_data.py --input ./my_data.jsonl --output-prefix ./data/my_data --vocab ./20B_tokenizer.jso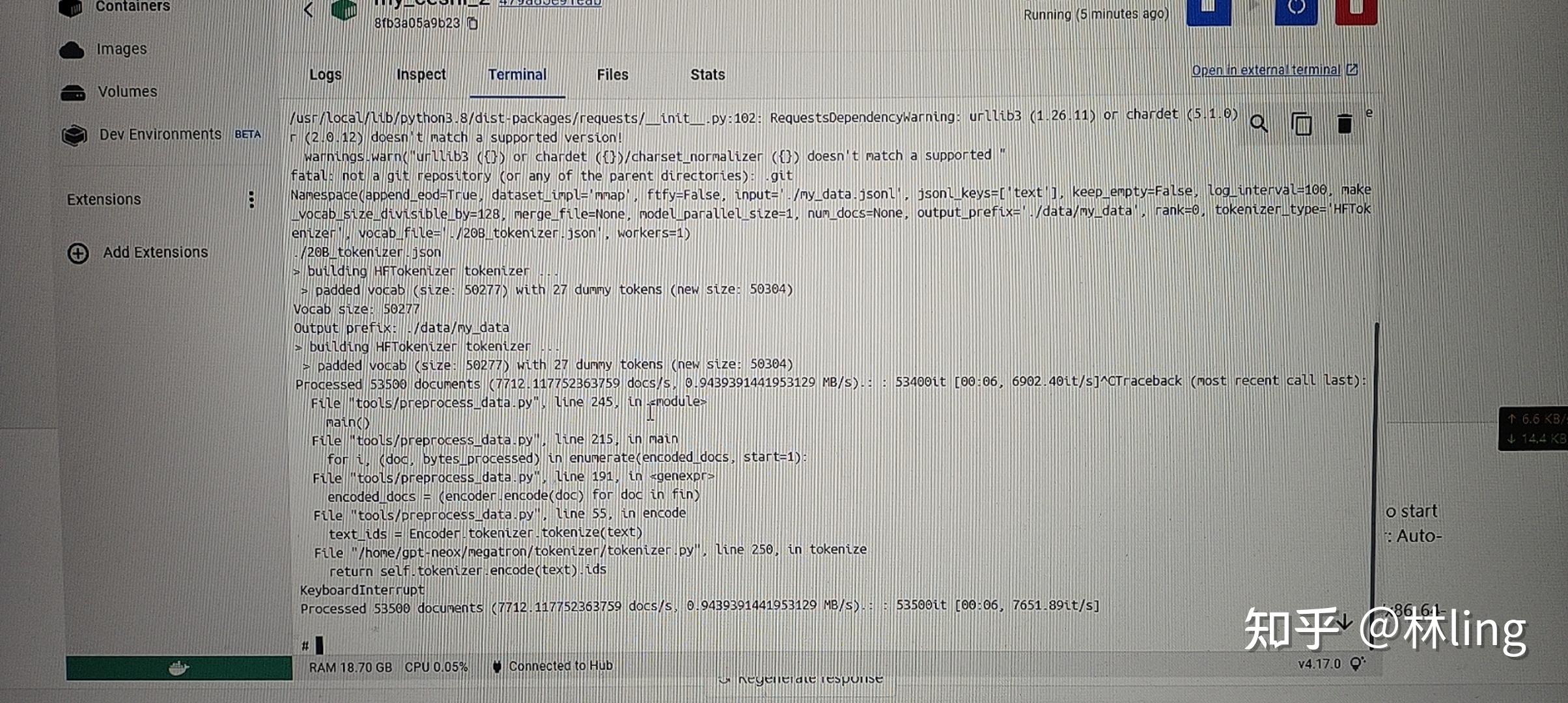 出现上图末尾中的进度条就行了,中间被我停止了所以报错了 2、训练ps:v4neo docker暂时不支持windows 训练,中间多多少少有些问题;而且转换损耗应该会比较大  反正这占比让我大吃一惊,百度上也搜了各种限制vmmem占比过高的解决方法,但是试了几种也没看到效果就懒得折腾了(已经解决) windows: 1、限制vmmem占比过高的方法 在用户目录下 C:\Users\Administrator(根据你自己的用户名来) 新建一个 .wslconfig文件 内容: [wsl2] memory=4GB #//分配给WSL内存3GB processors=1 # 使用的核心数量 swap=4GB # //设置交换分区4GB localhostForwarding=true 根据实际情况进行调整 2、下载镜像 docker pull linlinseo/rwkv-v4neo_lin:w10_v4neo好像占比20多个g,自己注意一下空间 3、创建容器 记得查看一下镜像的id docker images docker run --gpus all --name 容器名 -d -t 镜像id一般到这步没出错,那就没问题了。在别的win上还未测试,只在本人电脑上正常 4、进入文件路径 cd /home/其中有两个文件夹 RWKV-LM :直接git下来的代码,运行会报错,暂时没有研究 RWKV-LM-main:之前23年2月份的版本,进去后可以直接训练 cd /RWKV-LM-main/RWKV-v4neo5、训练: 预留了一个知乎的txt文本,比较乱,用来做测试使用,不用的话可以自己删掉 测试命令: python3 train.py --load_model "" --wandb "" --proj_dir "out" --data_file "/home/RWKV-LM/RWKV-v4neo/知乎问答文章合并.txt" --data_type "utf-8" --vocab_size 0 --ctx_len 512 --epoch_steps 5000 --epoch_count 500 --epoch_begin 0 --epoch_save 5 --micro_bsz 12 --n_layer 6 --n_embd 512 --pre_ffn 0 --head_qk 0 --lr_init 8e-4 --lr_final 1e-5 --warmup_steps 0 --beta1 0.9 --beta2 0.99 --adam_eps 1e-8 --accelerator gpu --devices 1 --precision bf16 --strategy ddp_find_unused_parameters_false --grad_cp 0实测是可以正常训练的,话不多说,上图,docker可以正常安装deepspeed模块并支持训练 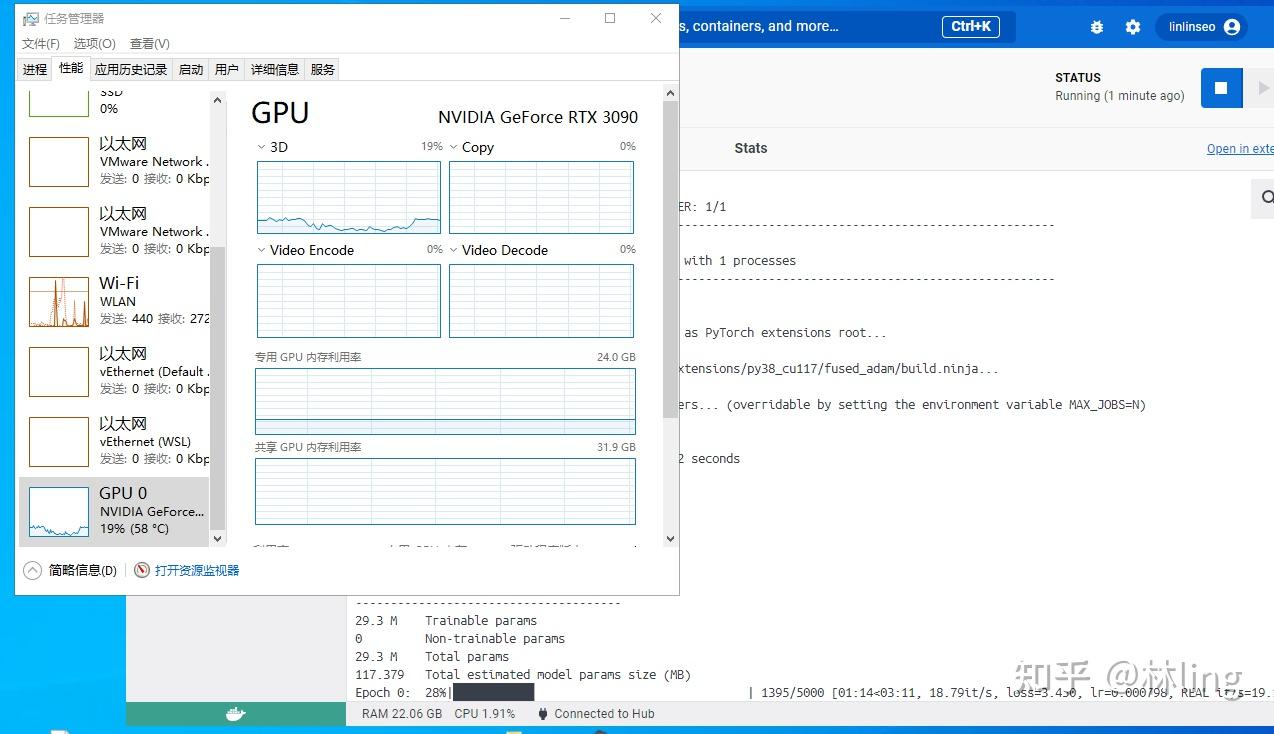 git最新的源码会报错,暂时未去研究,同样的配置跑之前的训练源码无问题  linux: 1、下载镜像(预计20g) docker pull linlinseo/rwkv-v4neo_lin:cuda11.1.1-cudnn8-devel-ubuntu20.042、创建容器(创建后默认进入容器,如不会自行百度) sudo docker run --gpus all -it /bin/bashps:docker images 查看镜像 3、进入文件路径 cd /home/RWKV-v4neo/ps:没记错的话应该是这个路径,如果出错了 自行查看一下路径并切换 4、训练指令 大多数参数可以直接在 train.py 文件中去调整修改 具体案例可以去 train.py 去查看 最后附上地址: GitHub - BlinkDL/RWKV-LM: RWKV is an RNN with transformer-level LLM performance. It can be directly trained like a GPT (parallelizable). So it's combining the best of RNN and transformer - great performance, fast inference, saves VRAM, fast training, "infinite" ctx_len, and free sentence embedding. |
【本文地址】
今日新闻 |
推荐新闻 |